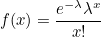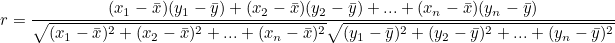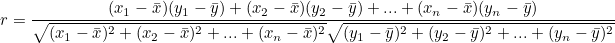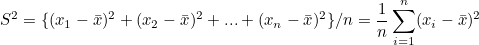> 포아송 분포 시행 횟수가 아주 많고, 사상 발생 확률이 아주 작을 때의 이항분포 공장에서 물건을 생산할 때 불량품의 수와 같이 시행 횟수는 많으나 적게 발생하는 사항의 확률 분포를 나타내는데 이용한다. e = 네이피어 상수, λ = 평균값(시행횟수 * 확률), x = 사상이 일어나는 횟수 평균값이 왜 시행횟수 * 확률일까는 이 블로그를 참고하자 이항분포의 기댓값은 시행횟수 * 확률이다. 포아송 분포의 람다값이 커지면, 즉 n 또는 p 값이 커지면 분산이 커지고, 분포곡선이 오른쪽으로 이동한다. 결과적으로는 정규분포에 가까워진다. > 카이제곱 분포 카이제곱 분포는 정규분포를 따르는 여러 데이터를 한 번에 취급하는 것이 가능하다. 이 때문에 분산분석에 이용할 수 있고 제곱하면 자유도에 따라 분포 형태가 ..