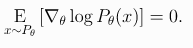제목 : Specification gaming: the flip side of AI ingenuity 날짜 : 2020년 4월 21일 URL : deepmind.com/blog/article/Specification-gaming-the-flip-side-of-AI-ingenuity Specification gaming: the flip side of AI ingenuity Specification gaming is a behaviour that satisfies the literal specification of an objective without achieving the intended outcome. We have all had experiences with specification gaming, ..