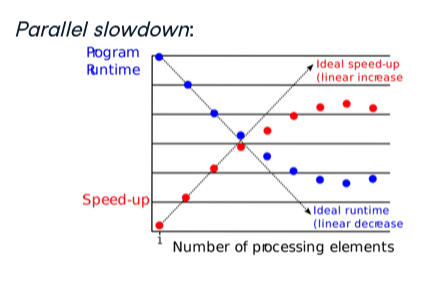
주제 Hadoop의 MapReduce와 HDFS, Hive, Spark에 대한 기본 개념을 배웠다. 하둡(Hadoop)은 Apache Software Foundation의 오픈 소스 프로젝트 모음이다. 이번 장에서는 하둡의 MapReduce와 HDFS에 대해 배운다. HDFS HDFS는 파일 시스템과 비슷하지만 파일이 여러 다른 컴퓨터에 있다는 것이 차이점이다. Amazon S3와 같은 클라우드 시스템이 HDFS 역할을 대체한다. MapReduce MapReduce는 대중화된 최초의 빅데이터 처리 패러다임 중 하나였다. 작업을 하위 작업으로 나누고 여러 처리 장치간 워크로드와 데이터를 분배한다. MapReduce의 결함 중 하나는 MapReduce 작업을 작성하는 것이 어렵다는 점이다. 이 문제를 해결하..