주제
Hadoop의 MapReduce와 HDFS, Hive, Spark에 대한 기본 개념을 배웠다.
하둡(Hadoop)은 Apache Software Foundation의 오픈 소스 프로젝트 모음이다.
이번 장에서는 하둡의 MapReduce와 HDFS에 대해 배운다.
HDFS
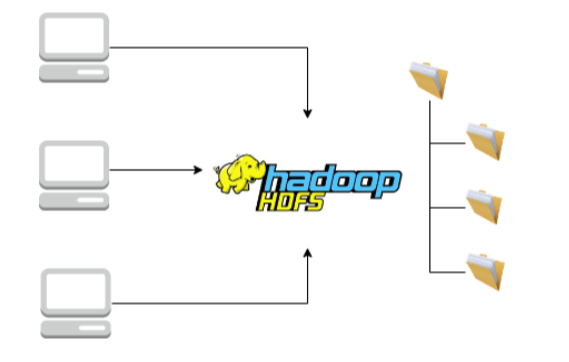
HDFS는 파일 시스템과 비슷하지만 파일이 여러 다른 컴퓨터에 있다는 것이 차이점이다.
Amazon S3와 같은 클라우드 시스템이 HDFS 역할을 대체한다.
MapReduce
MapReduce는 대중화된 최초의 빅데이터 처리 패러다임 중 하나였다.
작업을 하위 작업으로 나누고 여러 처리 장치간 워크로드와 데이터를 분배한다.
MapReduce의 결함 중 하나는 MapReduce 작업을 작성하는 것이 어렵다는 점이다.
이 문제를 해결하기 위한 도구 중 하나가 Hive이다.
Hive
- Hadoop 위에서 실행되는 하둡 에코시스템의 최상위 계층이다.
- Hive SQL을 사용하여 구조화돈 쿼리를 할 수 있다.
- 처음에는 MapReduce를 위한 도구였지만 지금은 여러 데이터 처리 도구와 통합된다.
Hive : 예제

SQL와 똑같아 보이지만 뒤에서는 Hive, Hadoop에서 실행된다.
Spark
- Spark는 컴퓨터 클러스터간 데이터 처리 작업을 배포한다.
- Spark는 메모리에서 가능한 한 많은 처리를 유지하려고 한다.예전에 Spark를 공부할 때, 최대한 연산을 미뤘다가 연산을 한다고 기억하는데... 그게 이 말인가..?
- Apache Software Foundation에서 관리한다.
RDD(탄력적 분산 데이터셋)
- Spark는 RDD에 의존한다.
- RDD를 튜플의 목록으로 생각할 수 있다.
- 변환 작업 :
map(),filter()→ 변환된 RDD 생성
- 액션 작업 :
count(),first()→ 단일 결과 생성
PySpark
사용자들은 Spark를 사용하기 위해 PySpark와 같은 인터페이스를 사용하게 된다.
- PySpark는 파이썬에서 Spark를 사용하기 위한 인터페이스
- scala, R에서도 Spark를 사용할 수 있다.
- DataFrame 추상화를 지원하기 때문에 pandas DataFrame과 매우 유사한 작업을 수행할 수 있다.
PySpark : 예제

Hive처럼 SQL 추상화를 사용하는 대신 DataFrame 추상화를 사용한다.
Uploaded by Notion2Tistory v1.1.0