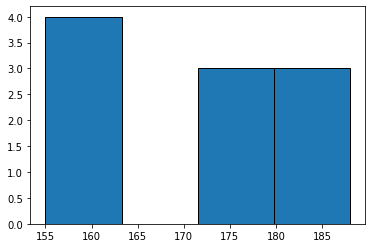
히스토그램은 데이터를 파악하기 위해 매우 유용한 시각화 방법이다. 예시를 들어 정리하는 것이 편하다. 10명의 키를 조사한 결과가 아래와 같다. 사람 키 1 180 2 175 3 155 4 160 5 161 6 178 7 188 8 182 9 163 10 172 151~160, 161~170, 171~180, 181~190 범위로 데이터를 표현하고 싶을 때 히스토그램이 적절하다. 히스토그램의 "bin"은 데이터를 담을 바구니 수라고 생각하면 편하다. 그렇다면, y축은 각 바구니에 담긴 데이터의 수라고 할 수 있다. 위 예시에서는 bins = 4가 될것이다. heights = [180,175,155,160,161,178,188,182,163,172] plt.hist(heights, bins=4, edgec..