Abstract
features 중 몇몇은 특정 모델이나 문제에 국한되어 동작한다. 반면, 대개 모델, 문제, 데이터셋에 적용이 가능한 universal features들도 존재한다.
- WRC : Weighted Residual Connections
- CSP : Cross Stage Partial connections
- CmBN : Cross mini Batch Normalization
- SAT : Self Adversarial Training
- Mish-activation
- Mosaic data augmentation
- DropBlock Regularization
- CIoU loss
위와 같은 방법을 적용하여 최신의 결과를 달성함.
Acc - MS COCO dataset, 43.5& AP
Speed - Tesla V100 65FPS
Introduction
CNN 기반 Object detector 대부분은 주로 추천시스템에 적용한다.
- 카메라를 이용한 주차 가능 공간 탐색 : 느리지만 정확한 model
- 차량 충돌 경고 : 속도는 빠르되 정확도 떨어지는 model
독립적인 프로세스 관리나 입력 투입 감소에도 적용된다.
대부분 정확한 최신의 뉴럴넷은 large mini-batch size로 여러개의 GPU를 사용하는 학습이 필요하다. 기존GPU에서 실시간 동작하고 학습 시 하나의 GPU로도 가능하도록 하는 것이 목표.
Goal
- 빠른 속도로 동작하는 obejct detector를 고안하고 병렬 계산을 최적화 하는것
- 기존의 GPU로 학습과 테스트를 수행할 때 누구나 YOLO v4의 성능을 얻을 수 있도록 함.
일반적인 object detector 구성

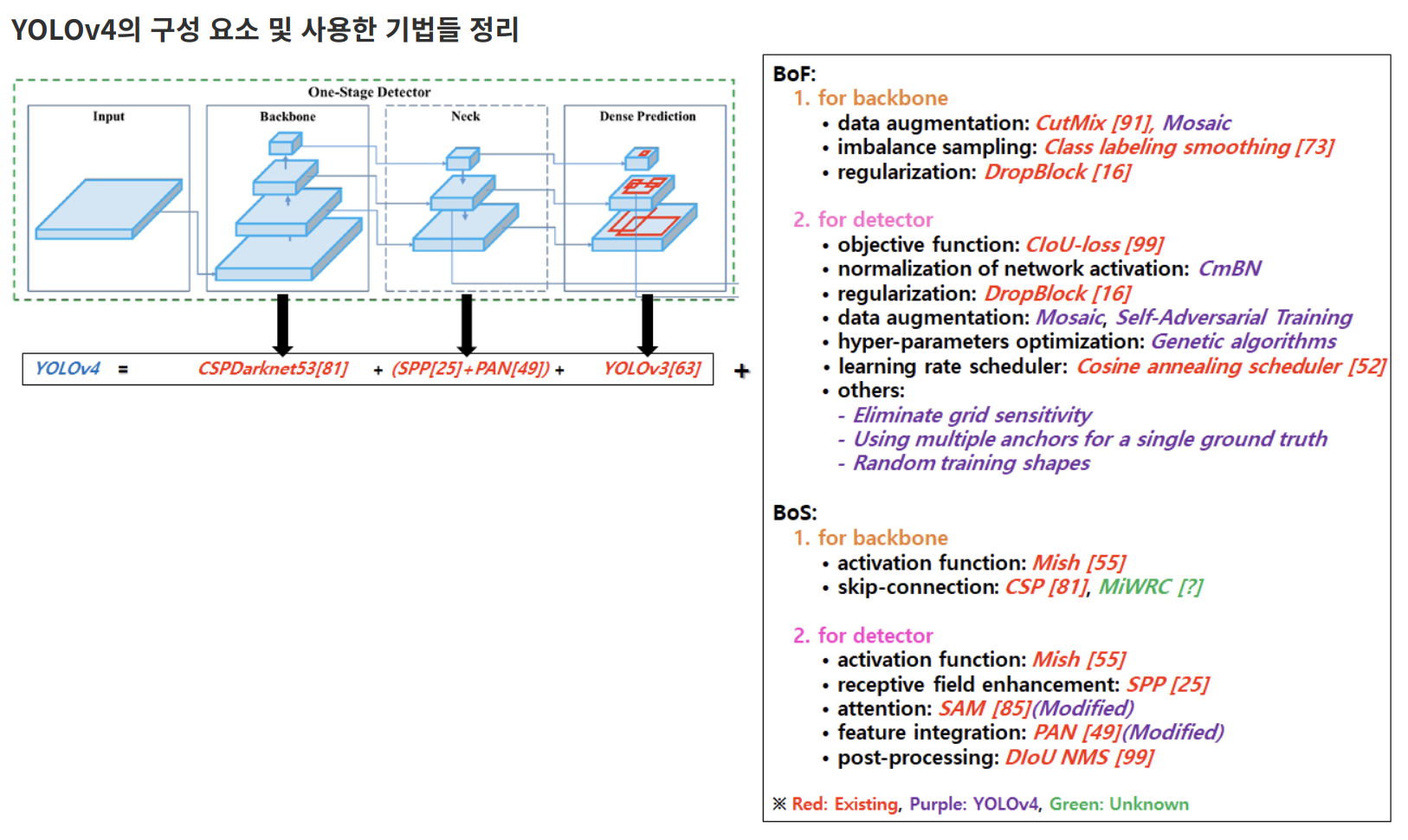
Bag of freebies
보통 object detector는 offline으로 training된다. object detection network 성능 향상을 위해 조합하여 사용할 수 있는 여러 기법을 통칭하는 말.
- data augmentation
- image augmentation을 통해 robust한 model을 만든다. 광학적 왜곡 - brightness, contrast, hue, saturation, noise 값 조절 기하학적 왜곡 - random scaling, cropping, flipping, rotating 조절
- object occlusion 문제를 시뮬레이션하는데 중점을 둔 연구들 이미지 내 사각형 영역을 랜덤하게 채우거나(random erase) 0으로 보완(cutout)한다. 여러 사각형 영역을 고르기도 한다.(hide-and-seek, grid mask)
- 여러 이미지를 함께 사용하는 방법 두개의 이미지를 사용해서 서로 다른 coefficient ratios를 곱하고 중첩시켜 label 조정함(MixUp) 잘라낸 이미지를 다른 이미지의 사각형 영역으로 덮고 mix area 크기에 따라 label 조정(CutMix)
- style transfer GAN을 사용해 CNN이 학습한 texture bias를 효과적으로 줄인다.
- Regularization
- DropOut, DropConnect, DropBlock
- Imbalance sampling
- 데이터셋 내 semantic distribution에 bias가 있는 문제를 해결하고자함.
- 서로 다른 클래스들간의 데이터 불균형 문제가 존재한다. hard negative example mining, online hard example mining, focal loss two-stage object detector에서는 hard negative example mining 또는 online hard example mining을 적용하여 해결 one-stage object detector는 dense한 prediction architecture를 이용하므로, example mining 기법의 적용이 불가 다양한 classes들 사이에 존재하는 data imbalance 문제를 해결하기 위해 focal loss를 적용
- 서로 다른 클래스들 내 연관 정도의 관계를 one-hot hard representation으로 표현하기 어려운 문제가 존재함. 학습을 위해 hard label을 soft label로 변환하여 모델을 강건하게 하는 label smoothing. soft label을 얻기위한 label refinement network 설계를 위해 knowledge distillation 개념 도입
- 데이터셋 내 semantic distribution에 bias가 있는 문제를 해결하고자함.
- objective function(BB regression)
- 보통 Mean Square Error 사용하여 center point와 BBox height, width를 직접적으로 regression한다.
- anchor-based에서는 offset을 추정한다.
- BBox 각 포인트 좌표값을 직접 추정하려면 이런 포인트를 독립적인 변수들로 취급해야하지만 object 자체에 대한 무결성이 고려되지 않는다.
- 이를 개선하기 위한 방법들은 다음과 같다. - IoU loss : 예측 BB와 GT BB의 coverage 고려, IoU는 scale 영향을 받지 않아서 L1, L2 loss 계산 시 loss가 scale에 따라 값이 변하는 문제를 해결한다. - GIoU loss : coverage area 외 object의 shape와 orientation을 포함한다. 예측된 BB와 GT BB를 동시에 커버할 수 있는 가장 작은 영역의 BB를 찾고 이 BB의 분모를 원래 IoU loss에서 사용하는 분모로 대체한다. - DIoU loss : object 중심 거리 고려 - CIoU loss : 겹침 영역, 중심점 사이의 거리, aspect ratio등을 동시에 고려함
Bag of Specials
추론 비용을 약간 증가시키고 정확도는 크게 향상시킴.
model 내 특정 feature를 향상시키는 plugin modules, 모델의 예측 결과를 선별하는 post-processing이 있다.
- plugin modules
- receptive field enhancement module
- SPP : Spatial Pyramid Matching에서 유래함. feature map을 여러개의 크기의 동등한 block으로 분할하여 공간적 피라미드를 형성하고 bag of word 연산으로 features를 추출한다. 이것이 SPM인데, 이를 CNN에 통합하고 bag of word 대신 max pooling 연산을 사용한다. output이 1D feature vector라서 Fully Convolution network에는 적용 불가능 비교적 큰 사이즈의 max pooling을 사용하여 backbone feature의 frecptive field를 효과적으로 증가시킬 수 있다.
- ASPP : 개선된 SPP와 ASPP의 차이는 kernel size에서 비롯된다.
- RFB : k size의 kernel의 여러개 dilated convolutions를 사용하여 ASPP보다 포괄적인 공간적 적용 범위를 얻을 수 있다.
- attention module
- channel wise attention과 point wise attention이 있다.
- Squeeze and Excitation(SE) : channel wise based, 이미지넷을 이용한 이미지 분류 문제에서 계산 비용 2%를 늘리고 acc를 1% 향상시킬 수 있지만 GPU 상에서 추론 시간은 10% 증가한다. 모바일 장치에서 아용하는것이 적합함.
- Spatial Attention Module(SAM) : point wise based, 0.1% 추가 계산으로 이미지넷 분류 문제에서 acc 성능을 0.5 향상 시킬 수 있고 GPU 상에서 추론 시간에 영향주지 않는다.
- activation function
- 좋은 activation function은 gradient를 효율적으로 전파하는 동시에, 너무 많은 계산 비용을 야기하면 안됨 ReLU : 전통적인 tanh 및 sigmoid activation function에서 흔히 발생하는 gradient vanish 문제를 상당부분 해결 ReLU 이후의 연구들 LReLU [54], PReLU [24], ReLU6 [28], Scaled Exponential Linear Unit (SELU) [35], Swish [59], hard-Swish [27], Mish [55] 역시, gradient vanish 문제를 해결하기 위해 제안 LReLU 및 PReLU: ReLU의 출력이 0보다 작을 경우 gradient가 0이 되는 문제를 해결하고자 함 ReLU6, hard-Swish: 특히, quantization networks를 고려하여 고안 SELU: neural network를 self-normalizing하기 위한 목적으로 제안 Swish, Mish: continuously differentiable한 activation function이라는 점이 주목해야 할 사항
- receptive field enhancement module
- post-processing
- 일반적으로 Non-Maximum Suppression을 사용한다. 동일한 object를 잘못 예측한 BB들을 필터링하고 응답이 높은 후보 BB들만 유지하는데 사용한다. 원래 제안된 NMS는 문맥 정보를 고려하지 않는다. R-CNN에서는 classification confidence score를 레퍼런스로 추가하고 confidence score의 순서에 따라 높은 score에서 낮은 score 순으로 greedy NMS를 수행한다.
- soft NMS : object occlusion 때문에 confidence score가 IoU socre와 함께 degradation 될 가능성을 고려한다.
- DIoU NMS : soft NMS를 베이스로 BBox screening process에 중앙 포인트에 대한 거리 정보를 추가한다.
- 위 방법들은 캡쳐된 image feature를 직접 참고하지 않기 때문에 Anchor-free 기법에서는 post-processing이 필요하지 않게 된다.
Methodology
BFLOP 보다는 병렬 계산을 위해 생산 시스템 및 최적화 관점에서 빠르게 동작하는 neural network를 개발하는 것이 목표이며, 실시간 neural network을 위한 2개의 options을 제시
- GPU의 경우 convolutional layers 내 group의 수가 작은(1-8) CSPResNeXt50 / CSPDarknet53 등을 이용
- VPU의 경우 grouped-convolution은 사용하지만, Squeeze-and-excitement (SE) blocks은 사용하지 않음. 특히 EfficientNet-lite / MixNet [76] / GhostNet [21] / MobileNetV3 등의 모델들을 포함함
네트워크 구조 선택
goal
input resolution, # conv layer, # parameters, # output of layer 사이에서의 optimal한 구조를 선택
- ImageNet에서는 CSPResNext50 > CSPDarknet53
- MS COCO에서는 CSPResNext50 < CSPDarknet53
receptive field를 들릴 수 있는 추가 모듈 블럭과 서로 다른 detector levels을 위한 서로 다른 backbone levels로부터 parameter aggregation을 위한 optimal 방법 선택
- FPN, PAN, ASFF, BiFPN
- 분류를 위한 참조 모델들이 항상 detector에서도 최적은 아니다. classification과 다르게 detection에서는 아래와 같은 내용이 필요하다.
- 더 큰 network resolution : 작은 크기를 갖는 다수의 객체들 검출의 위해 필요
- 더 많은 layer 수 : 커진 input을 수용할 수 있는 receptive field가 필요
- 더 많은 parameter 수 : 서로 다른 크기의 다수 객체들을 검출하기위해 더 많은 파라미터가 필요
CSPResNext50: 단지 16개의 3 x 3 convolutional layers와 425 x 425 크기의 receptive field와 20.6 M의 parameters를 가짐
CSPDarknet53: 29개의 3 x 3 convolutional layers와 725 x 725 크기의 receptive field와 27.6 M의 parameters를 가짐
위와 같은 이론적 근거는 수많은 실험을 통해 CSPDarknet53 neural network가 detector를 위한 2개의 backbone 중에 최적의 model임을 보여줌
크기 다른 receptive field의 영향
→ object 크기가 커지면? 전체 객체들을 보다 많이 볼 수 있다.
→ 네트워크 크기가 커지면? 객체 주변의 문맥을 많이 볼 수 있다.
→ 네트워크 크기가 초과되면? image point와 최종 activation 사이의 연결 개수가 증가한다.
본 연구에서는 CSPDarknet53에 SPP block을 추가함.
→ receptive field를 늘릴 수 있음
→ 가장 중요한 context features를 분리할 수 있다.
→ 네트워크 동작 속도를 거의 줄이지 않음
최종적으로 선택된 기법들
- backbone
- CSPDarknet53
- neck
- addtional blocks: SPP
- path-aggregation blocks: PANet
- head
- YOLOv3(anchor-based)
Cross-GPU Batch Normalization (CGBN 또는 SyncBN) 또는 고가의 특수 장비 등을 사용하지 않으므로, GTX 1080Ti 또는 RTX 2080Ti 등의 기존에 사용하던 GPU를 이용하여 누구나 최신의 결과를 재연 가능
BoF(Bag of Freebies) 후보
- Bounding box regression loss: MSE, IoU, GIoU, CIoU, DIoU
- Data augmentation: CutOut, MixUp, CutMix
- Regularization method: DropBlock
- DropBlock의 저자들이 YOLOv4를 이용하여 다른 방법들과 비교했을 때 우수한 성능을 보인다는 것을 입증했으므로, DropBlock을 주저없이 적용
BoS(Bag of Special) 후보
- Activations: ReLU, leaky-ReLU, Swish, Mish
- PReLU와 SELU는 훈련이 많이 어려우므로 제외
- ReLU6는 특별히 quantization network을 위해 고안되었으므로 제외
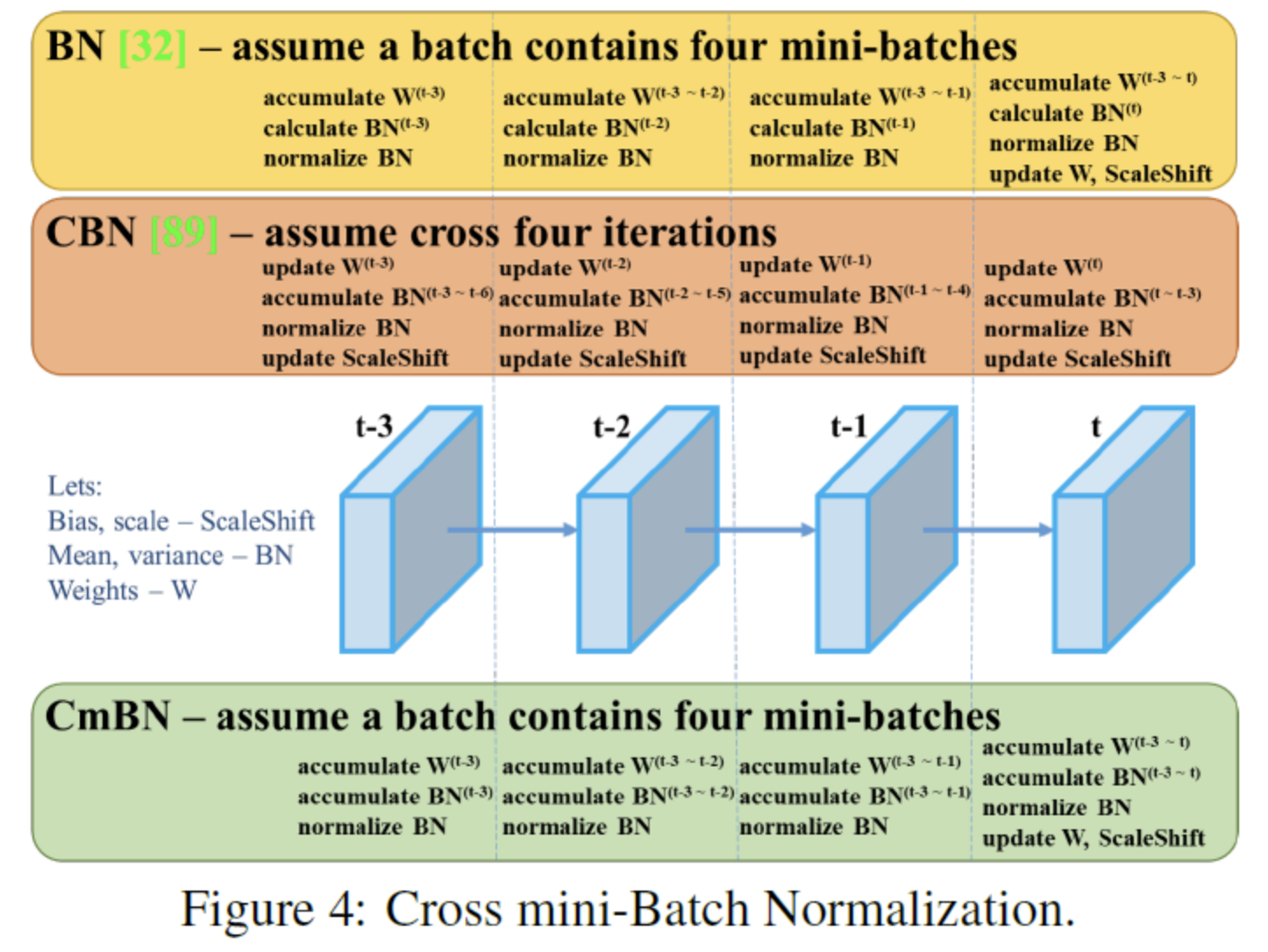
- Normalization of the network activations by their mean and variance: Batch Normalization (BN) [32], , Filter Response Normalization (FRN) [70], Cross-Iteration Batch Normalization (CBN) [89]
- 하나의 GPU만을 이용한 훈련 전략에 중점을 두고 있으므로, syncBN은 제외
- Skip-connections: Residual connections, Weighted residual connections, Multi-input weighted residual connections, Cross stage partial connections (CSP)
추가 개선
제안한 detector를 하나의 GPU를 이용한 training 시 보다 적합하게 만들기 위해, 아래와 같이 추가적인 설계 및 개선을 수행
- Mosaic과 Self-Adversarial Training (SAT) 등의 새로운 data augmentation 기법을 도입
- genetic algorithms을 적용하여 최적의 hyper-parameters를 선택
- 효율적인 training과 detection을 위해 존재하는 기법들을 제안한 detector에 적합하도록 수정
- modified SAM, modified PAN, Cross mini-Batch Normalization (CmBN)
BoF
- Mosaic : CutMix는 2개의 이미지를 mix, Mosaic은 4개의 이미지를 mix한다. 이를 통해 normal한 context 외부의 object들도 검출 가능하다. 또한 batch normalization은 각 레이어 상에서 서로 다른 4개의 이미지들에 대한 activation 통계를 계산할 수 있다. 따라서 큰 크기의 mini batch에 대한 필요성을 줄일 수 있다.

- Self-Adversarial Training
- 두 단계의 forward, backward 단계로 동작함
- 1 단계 : 뉴럴넷은 weight 대신 원본 이미지를 변경
- 2 단계 : 뉴럴넷은 변경된 이미지에서 정상적인 방식으로 object를 detection하도록 훈련된다.
BoS
- Cross mini-Batch Normalization : CBN의 변경된 version으로, 단일 batch에서 mini-batches 사이에 대한 통계를 수집한다.
- SAM을 spatial-wise attention에서 point-wise attention으로 변경(그림 5)
- PAN의 shortcut connection을 concatenation으로 교체(그림 6)

Uploaded by Notion2Tistory v1.1.0