YOLO v1, v2에 이어 세번째 버전인 v3 리뷰글을 작성한다.
YOLOv3는 v2에서 개선된 버전으로 v2를 먼저 읽고 v3를 읽는 것을 추천한다.
Bounding box prediction
YOLOv1에서는 anchor box 없이 즉시 bounding box 정보를 예측했다.
좀 더 안정적인 학습을 위해 YOLOv2에서는 anchor box를 사용하여 BBox를 예측하는 방법을 사용한다.
그리고 학습 과정에서 loss function은 SSE 형태의 에러함수를 사용한다.

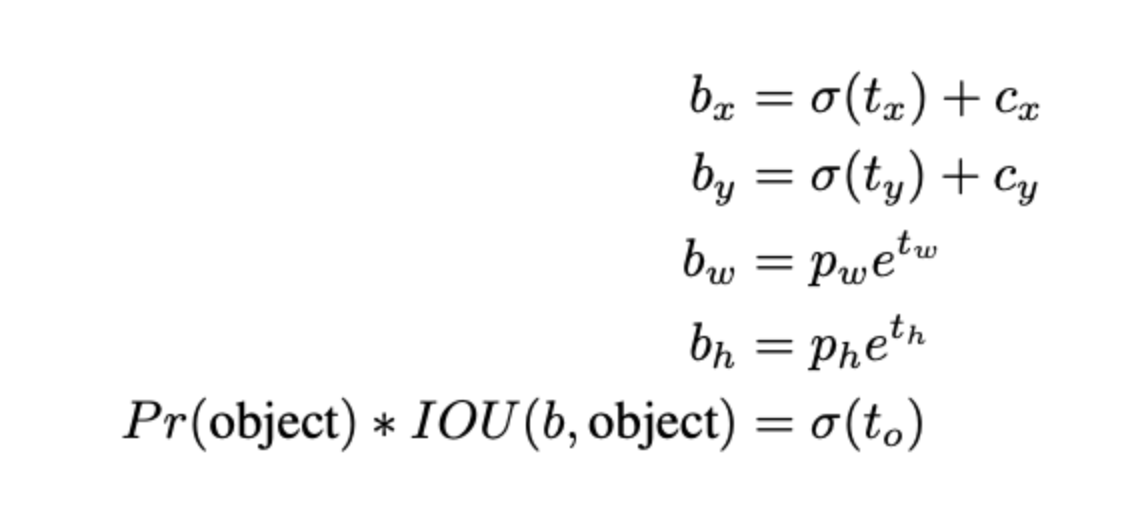
YOLO v3는 logistic regression을 사용해 각 bbox를 위한 objectness score를 예측한다.
우선순위의 bbox가 다른 bbox보다 GT bbox와 많이 겹친다면(IoU가 높다면) score는 1이 된다.
그 외의 박스들은 무시한다. IoU threshold는 0.5를 사용하여 0.5 이상인 우선순위의 bbox를 사용하게 된다.
faster r-cnn과 달리, 각 GT 객체 당 하나의 bbox prior를 할당한다. 만약 할당된 bbox prior가 없으면, loss는 objectness에 대해서만 발생하게 된다. 좌표나 클래스 예측에 대한 loss는 발생하지 않는다.
Class prediction
multilabel classification을 사용해서 각 박스의 클래스들을 예측한다.
multilabel classification은 한 이미지에 여러 라벨을 예측하는 것이다.
softmax를 사용하면 좋은 성능이 나오지 않아서 독립적으로 logistic classifiers를 사용한다. (Sigmoid, ReLU 등..)
softmax에서는 categorical cross-entropy loss를 사용하는데, class가 2가 되면 sigmoid나 softmax나 같은 식이 되기 때문에
sigmoid function을 사용하고 나서 주로 binary cross-entropy loss를 사용한다.
Predictions Across Scales
YOLOv3에서는 3개의 스케일에서 box 예측을 한다.
마지막 예측에서 3차원 텐서형태로 bounding box, objectness, class prediction 정보를 인코딩한다.
각 스케일에서 3개의 box를 예측하는 텐서는 N*N*[3*(4+1+80)]형태가 된다. 4는 바운딩박스의 offsets, 1은 objectness, 80은 classification에 대한 정보이다. (N은 그리드 갯수)
그리고 전 처럼 앵커박스 결정을 위해 k-means clustering을 사용한다. 3개의 스케일에서 3개의 박스 예측을 하기 때문에 3*3=9개의 앵커박스를 사용하게 된다.
Feature Extractor
YOLOv3에서는 feature를 추출하기 위해 새로운 네트워크를 사용한다.
YOLOv2에서는 VGG의 불필요한 연산을 개선한 새로운 classification model로 Darknet-19를 소개했다.
YOLOv3에서는 53개의 Conv layer를 추가하여 Darknet-53을 소개한다.
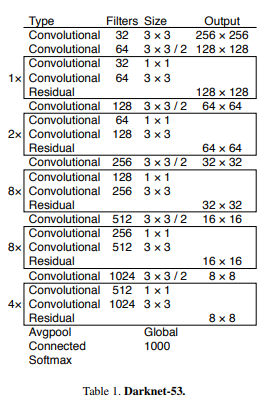
Darknet-53은 ResNet의 skip connection을 도입했으며, Darknet-19, ResNet-101, ResNet-152보다 좋은 성능을 보인다.
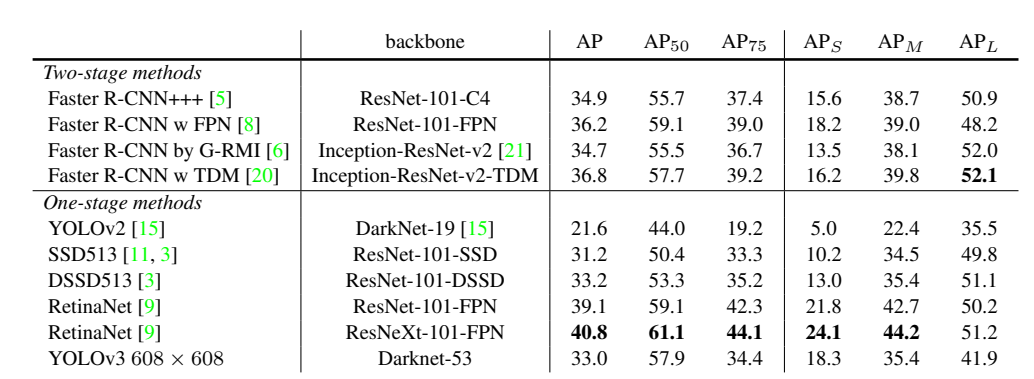
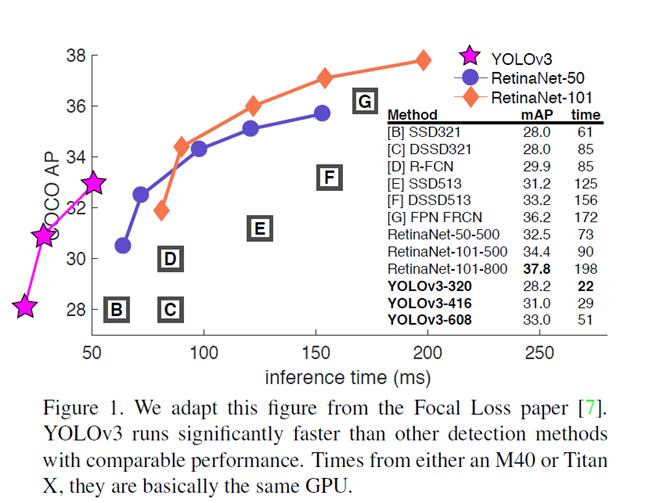
'Machine Learning > For CV' 카테고리의 다른 글
| YOLOv4 : Optimal Speed and Accuracy of Object Detection (0) | 2021.09.14 |
|---|---|
| Face Landmark Detector - Dlib (0) | 2021.07.14 |
| [YOLO 정독] YOLO v2 (YOLO 9000) (0) | 2021.06.14 |
| Vision Transformer 모델들은 왜 데이터셋이 많아야할까? Inductive bias (0) | 2021.06.09 |
| [YOLO 정독] YOLO v1 (0) | 2021.05.29 |