Transformer를 vision task를 위해 도입한 논문들을 보면 이런 말을 자주 본다.
트랜스포머 모델들이 CNN 기반 모델보다 inductive bias가 부족하다.
Inductive bias가 뭔데..?
구글에 그대로 검색해보면 다음과 같이 설명한다.
학습 알고리즘의 귀납적 편향은 학습자가 경험하지 않은 주어진 입력의 출력을 예측하는 데 사용하는 가정의 집합입니다. 기계 학습에서 특정 목표 출력을 예측하는 방법을 배울 수있는 알고리즘을 구성하는 것을 목표로합니다.
대충 억지로 이해해보면,, 경험하지 않은 입력에 대한 예측을 위해 사용하는 가정이다.. 즉, 학습하지 않은 데이터가 들어갔을 때 잘 예측하기 위한 가정이구나!
이게 Transformer랑 CNN이랑 무슨 상관인지 이해하려면 CNN의 특성을 알 필요가 있다.
CNN은 아래 그림과 같이 Convolution 연산을 하는 layer를 겹겹이 쌓아서 만든 뉴럴넷이다.

Convolution 연산은 글로벌하게 이미지를 보기보단 로컬 영역에서 이미지 내 공간적인 정보를 추출하는데 탁월하다.
그래서 CNN은 글로벌한 영역에 대한 처리가 어려워서 최대한 넓은 영역에서의 feature를 볼 수 있도록 receptive field를 키우기 위한 연구들을 많이 진행함.
Transformer는 CNN과 다르다.

이미지를 Path형태로 잘라서 positional embedding을 하여 input으로 사용한다. 그리고 self-attention 형태의 트랜스포머 인코더를 사용한다.
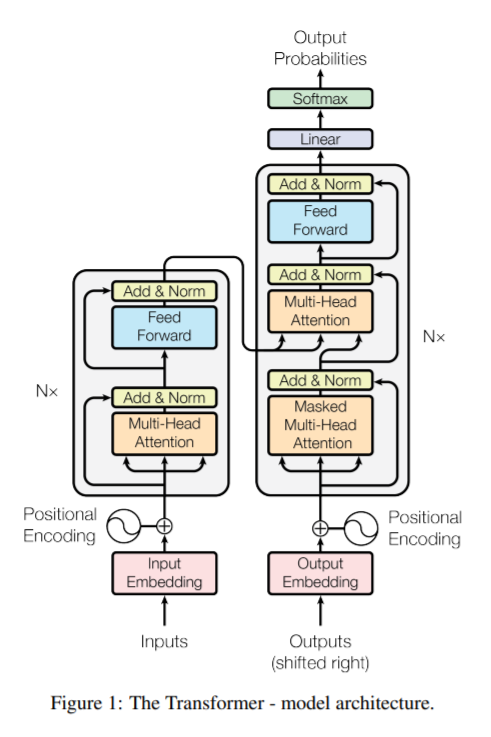
Image에 대한 여러가지 정보들을 활용하지만 convolution처럼 locality 가정이 없기 때문에 inductive bias가 부족하다.
결론적으로, Transformer 모델은 대부분의 데이터에 대한 예측은 robust하게 하지만 학습을 잘 시키려면 데이터셋이 커야한다.
'Machine Learning > For CV' 카테고리의 다른 글
| [YOLO 정독] YOLOv3 : An Incremental Improvement (0) | 2021.06.20 |
|---|---|
| [YOLO 정독] YOLO v2 (YOLO 9000) (0) | 2021.06.14 |
| [YOLO 정독] YOLO v1 (0) | 2021.05.29 |
| [VISION 논문 읽기] simple copy-paste is a strong data augmentation method for instance segmentation (0) | 2021.02.02 |
| MTCNN으로 Face landmark 추출 (0) | 2020.12.03 |