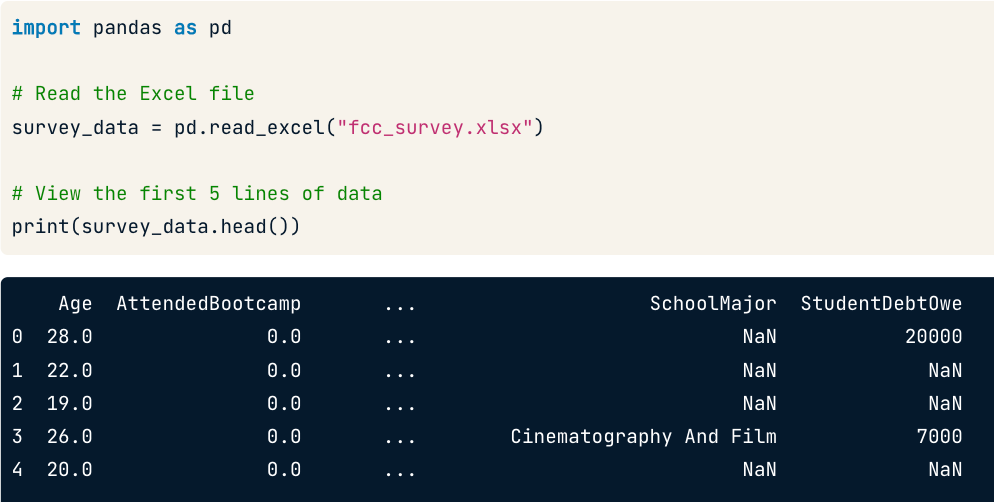
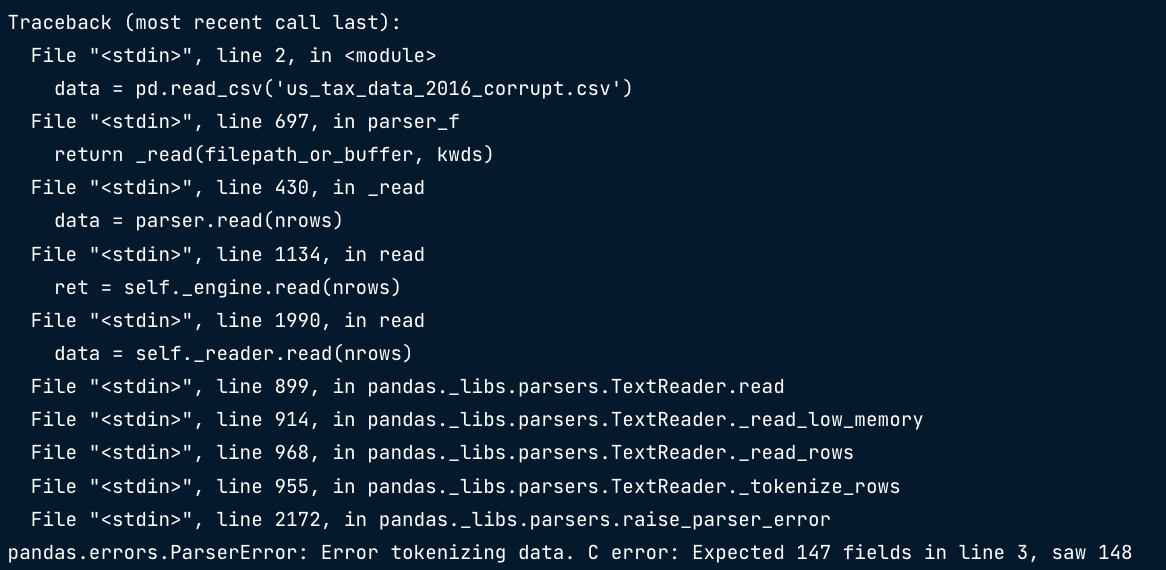
주제 엑셀파일의 데이터를 판다스의 데이터프레임으로 읽는 법에 대해 배웠다. 스프레드시트 엑셀 파일로도 잘 알려져 있음. 데이터 프레임과 마찬가지로 행,열로 구성된 데이터 셀과 테이블 정보를 구성한다. 플랫파일과 다르게 형식이나 공식 적용이 가능하다. 스프레드시트는 통합 문서에 여러 개가 있을 수 있다. 스프레드시트 로드 판다스에서 read_excel() 을 사용해서 스프레드시트의 데이터를 로드할 수 있다. 행과 열 선택해서 읽기 스프레드 시트에 생각하는 대로 곧바로 깔끔하게 데이터가 들어있지 않을 수 있다. 메타 데이터 같은 데이터가 헤더에 포함되어 있을 수 있다. read_excel()은 read_csv()와 유사하지만 다른 점들이 있다. nrows : 읽을 행의 수 제한 skiprows : 건너 뛸 ..