

이번 05 문제도 지난 04처럼 코드가 아닌 이론을 설명하는 문제이다.
Loss function과 Optimizer에 대해서 설명하면 된다.
loss function
loss function은 ground truth(정답)과 생성한 모델의 예측값 간의 차이를 나타내는 함수.
cross entropy(classification), mse(regression)가 대표적이다.

cross entropy를 잘 설명해주는 블로그를 참고하면 좋을 것 같다.
https://ratsgo.github.io/deep%20learning/2017/09/24/loss/
딥러닝 모델의 손실함수 · ratsgo's blog
이번 글에서는 딥러닝 모델의 손실함수에 대해 살펴보도록 하겠습니다. 이 글은 Ian Goodfellow 등이 집필한 Deep Learning Book과 위키피디아, 그리고 하용호 님의 자료를 참고해 제 나름대로 정리했음을 먼저 밝힙니다. 그럼 시작하겠습니다. 딥러닝 모델의 손실함수로 음의 로그우도(negative log-likelihood)가 쓰입니다. 어떤 이유에서일까요? 딥러닝 모델을 학습시키기 위해 최대우도추정(Maximum Likelihood Es
ratsgo.github.io
mse(mean sqaure error)는 (정답-예측값)의 제곱을 전부 더해서 그 수만큼 나눈 것이다.
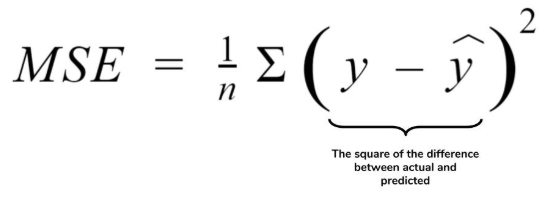
optimizer
loss function으로 구한 loss값을 최소화(optimization)하기 위해서 Gradient Descent를 하게 되는데 이 Gradient Descent를 하기 위한 함수들이 optimizer이다.
SGD, RMSProp, Adam 등이 있다.
gradient descent optimization algorithm을 공부해본 사람들은 한번쯤 봤을 유명한 짤이다.


https://ruder.io/optimizing-gradient-descent/
An overview of gradient descent optimization algorithms
Gradient descent is the preferred way to optimize neural networks and many other machine learning algorithms but is often used as a black box. This post explores how many of the most popular gradient-based optimization algorithms such as Momentum, Adagrad,
ruder.io
'DAFIT > 902 - 딥러닝으로 은하분류하기' 카테고리의 다른 글
| <DAFIT> 02 딥러닝으로 은하 분류하기 07 - Accuracy (0) | 2019.10.29 |
|---|---|
| <DAFIT> 02 딥러닝으로 은하 분류하기 06 - Validation, Evaluate (0) | 2019.10.29 |
| <DAFIT> 02 딥러닝으로 은하 분류하기 04 - Relu, Softmax (0) | 2019.10.29 |
| <DAFIT> 02 딥러닝으로 은하 분류하기 03 - CNN (0) | 2019.10.29 |
| <DAFIT> 02 딥러닝으로 은하 분류하기 02 - Image Data Generator (0) | 2019.10.29 |