참고도서 : python을 이용한 개인화 추천 시스템 - 임일
Content-base Filtering (CB; 내용 기반 필터링)
CB는 제품의 내용을 분석해서 추천하는 기술.
특히나 텍스트 정보가 많은 책, 뉴스에 많이 사용되는 추천 방법이다.
CB 절차
- 아이템 간 유사도 구하기
- 추천 대상자(user)가 선호하는 아이템 선정
- 선호 아이템과 유사도가 가장 높은 N개 아이템 찾기
- N개 아이템을 추천
이 절차에서 발생하는 이슈
- 유사도 함수 정하기
- 유사도 함수는 여러가지가 있다.
- N을 몇으로 설정할 것인지
- N이 많을수록 추천 성능이 올라가겠지만, 몇 개가 최적인지 알 수 없다.
- N개 아이템 각각 유사도 높은 아이템들이 있을텐데, 이것들을 어떻게 조합할 것인지
영화 데이터를 통해 CB 추천 시스템을 만들어보자.
import pandas
from sklearn.feature_extraction.text import TfidfVectorizer # 유사도 측정을 위한 전처리
from sklearn.metrics.pairwise import cosine_similarity # 유사도 함수 (코사인유사도)# 데이터 읽기
movies = pd.read_csv('./데이터-2판/movies_metadata.csv', encoding='latin-1', low_memory=False)
movies = movies[['id','title','overview']]
movies.head(10)
영화 id, 제목, 줄거리 정보가 있는 데이터셋이다.
#preprocessing
movies.dropna(inplace=True) # 결측치 제거
movies['overview'].fillna(' ',inplace=True) # 줄거리가 비어있는 부분은 빈칸으로 대체각 영화 간 유사도를 구할 수 있도록 전처리 과정이 필요하다.
왜냐? 전처리하지 않고 사용한다면, 정상 데이터 속에 섞인 이상치들이 모델 성능에 어떤 영향을 끼칠지 모르기 때문에 최대한 데이터를 깔끔하게 정제해서 추천시스템에 적용해야 정확성이 높아진다.
tfidf = TfidfVectorizer(stop_words='english') # stop_words='english'로 설정
tfidf_matrix = tfidf.fit_transform(movies['overview']) # tf-idf 계산특정 영화의 각 줄거리 내용 중 필요 없는 단어들은 추천 시스템이 알고 있어봤자 방해만 되는 요소일 것이다.
이런 요소들을 "불용어"라고 하고, tf-idf 는 이러한 불용어들의 가중치를 줄이면서 문장 속 단어들의 중요도를 계산하는 방법이다.
tf-idf 값이 크다는 건, 특정 문서에서 단어 빈도가 높고 전체 문서들 중 그 단어를 사용하는 빈도가 낮다는 것이다.
영화 줄거리의 핵심 단어를 추출하기 위해 TfidfVectorizer()를 사용하자.stop_words 는 불용어를 설정할 수 있는 파라미터다.'english' 로 하면 영어를 불용어로 설정한다.
영화 줄거리 overview 컬럼 데이터의 tf-idf 값을 계산한다.
cosine_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
cosine_sim = pd.DataFrame(cosine_sim, index=movies.index, columns=movies.index)tf-idf 값을 가지고 코사인 유사도를 통해 영화 간 유사도를 구한다.
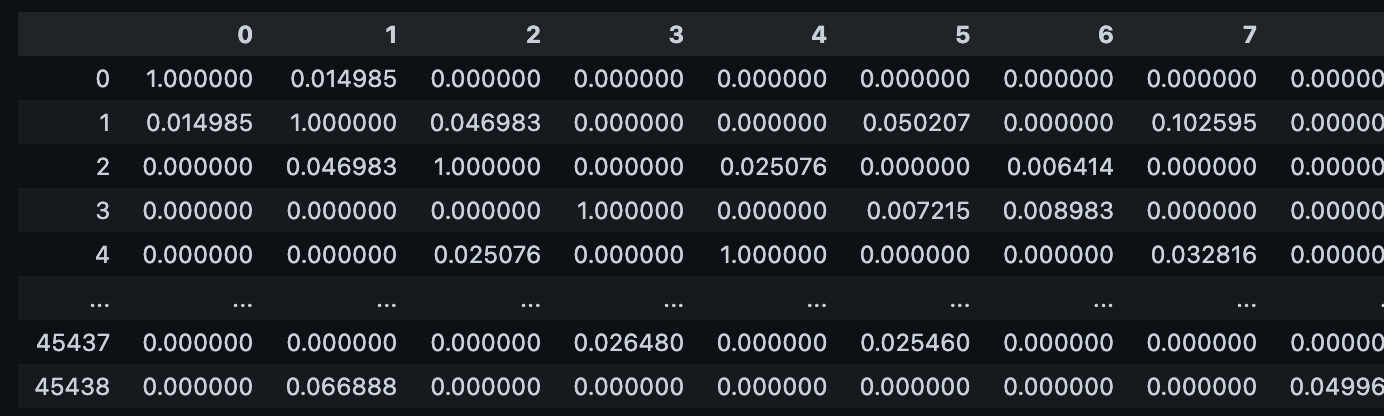
영화 간 유사도를 편하게 행렬형태로 보기 위해 데이터프레임으로 만들었다.
각 인덱스, 컬럼에 있는 숫자들은 영화의 인덱스이다.
현재 첨부된 이미지 데이터로만 봤을 때, index가 1인 영화와 유사도가 높은 2개 영화를 꼽는다면,
나 자신을 제외한 0번 영화(0.14985)와 7번 영화(0.102595) 가 될 것이다.
우리는 유사도가 높은 영화 제목을 알고싶은 것이니까 영화제목과 인덱스값을 매칭시킬 수 있도록 변수를 하나 만들자.
indices = pd.Series(movies.index, index=movies['title'])
마지막으로 내가 입력한 영화제목과 유사도가 높은 N개의 영화제목을 반환해주는 함수를 통해 추천 시스템 코드 작성을 마무리한다.
def content_recommender(title, n):
idx = indices[title]
sim_scores = cosine_sim[idx]
sim_scores = sim_scores.sort_values(ascending=False)[1:n+1] # [1:n+1] -> 나 자신을 제외한 나머지 영화들
return movies.loc[sim_scores.index]['title']
print(content_recommender('The Lion King', 5))
print(content_recommender('The Dark Knight Rises', 10))

'추천시스템' 카테고리의 다른 글
| TF-IDF (0) | 2023.01.17 |
|---|---|
| 집단별 추천해보기 (협업필터링 아님!) (0) | 2023.01.15 |
| 사용자 정보가 없을때는? Best-Seller 방식! (0) | 2022.12.18 |
| 추천시스템의 개념과 기본 알고리즘의 개념 (0) | 2022.12.18 |