참고도서 : python을 이용한 개인화 추천 시스템 - 임일
집단별 추천 시스템
취향이 아니라 직업, 성별 등 단순 통계적으로 구분할 수 있는 집단으로 구분하여 추천 시스템을 만들어보자.

이런 순서로 구성해야 한다.
import pandas as pd
import numpy as np
u_cols = ['user_id','age','sex','occupation','zip_code']
users = pd.read_csv('./u.user', sep='|', names=u_cols, encoding='latin-1')
i_cols = ['movie_id','title','release date',' video release date','IMDB URL','unknown','action','adventure','animation','children\'s','comedy','crime','documentary','drama','fantasy','film-noir','horror','musical','mystery','romance','sci-fi','thriller','war','western']
movies = pd.read_csv('./u.item', sep='|', names=i_cols, encoding='latin-1')
r_cols = ['user_id','movie_id','rating','timestamp']
ratings = pd.read_csv('./u.data',sep='\t',names=r_cols,encoding='latin-1')
ratings = ratings.drop('timestamp',axis=1) # 타임스탬프 컬럼 제거
movies = movies[['movie_id','title']] #영화 아이디랑 제목만 사용앞 포스팅과 같은 데이터를 사용하기 때문에 로드하는 방식도 똑같다.
#train/test set 분리
from sklearn.model_selection import train_test_split
x = ratings.copy()
y = ratings['user_id']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, stratify=y)학습 데이터와 평가 데이터를 나누기위해 sklearn을 사용한다.
# 정확도함수
def RMSE(y_true, y_pred):
return np.sqrt(np.mean((np.array(y_true)-np.array(y_pred))**2))
# 모델 예측 후 에러값 측정
def score(model):
id_pairs = zip(x_test['user_id'], x_test['movie_id'])
y_pred = np.array([model(user, movie) for (user, movie) in id_pairs])
y_true = np.array(x_test['rating'])
return RMSE(y_true, y_pred)추천 모델의 추천 성능을 확인할 수 있는 함수를 작성한다.
# 학습 데이터(x_train)의 full matrix 만들기
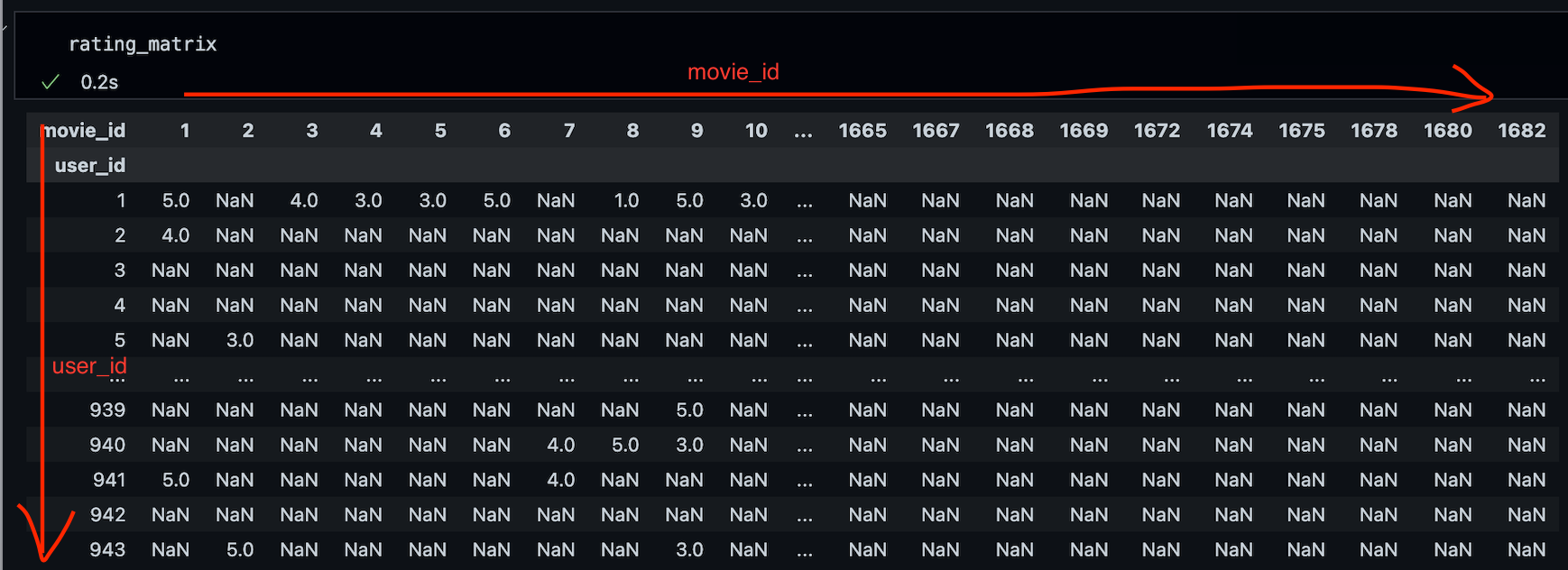
rating_matrix = x_train.pivot(index='user_id',columns='movie_id',values='rating')rating matrix는 다음과 같이 생겼는데, 각 셀은 user별로 전체 영화에 대해서 준 평점이다.
먼저, 앞서 작성했던 베스트셀러 방식을 확인해보자.
def best_seller(user_id, movie_id):
try :
rating = train_mean[movie_id]
except:
rating = 3.0
return rating
train_mean = x_train.groupby(['movie_id'])['rating'].mean() # 영화별 평균 평점
score(best_seller)
베스트셀러방식은 1.02가 나왔다.
앞 포스팅보다 RMSE 값이 커졌는데(커지면 성능이 안좋다는 것임), 그 이유는 Train, Test set을 분리해서 test set에 대해서만 평가를 했기 때문이다.
전에 봤던 데이터(Train set)라면 잘 판단할 수 있지만 처음보는 데이터(Test set)를 가지고 예측을 하자니, 잘 못하는 것이다.
그럼 특정 기준을 가지고 사용자 집단을 분리하여 추천하는 모델을 만들어보면 더 좋은 성능을 가지지 않을까?
먼저, 간단히 "성별" 로 사용자를 나눠서 예측해보는 모델을 만들었다.
# 성별기준 추천
merged_ratings = pd.merge(x_train, users)
users = users.set_index('user_id')
# 영화별 각 성별의 평균평점 구하기
g_mean = merged_ratings[['movie_id','sex','rating']].groupby(['movie_id','sex'])['rating'].mean()
def cf_gender(user_id, movie_id):
if movie_id in rating_matrix:
gender = users.loc[user_id]['sex']
if gender in g_mean[movie_id]:
gender_rating = g_mean[movie_id][gender]
else:
gender_rating = 3.0
else:
gender_rating = 3.0
return gender_rating
score(cf_gender)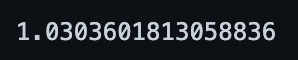
오히려 나빠졌다.
이 말은 성별이 영화 추천 정확도 개선에 영향이 없다는 것이다.
그럼 다른 변수를 기준으로 집단을 나눠보자.
# 직업기준 추천
# 성별 추천 코드를 수정해서 직업에 따라 집단을 나눠 예측값을 구하는 함수와 정확도 계산하는 코드 작성해보기
o_mean = merged_ratings[['movie_id','occupation','rating']].groupby(['movie_id','occupation'])['rating'].mean()
def cf_job(user_id, movie_id):
if movie_id in rating_matrix:
job = users.loc[user_id]['occupation']
if job in o_mean[movie_id]:
job_rating = o_mean[movie_id][job]
else:
job_rating = 3.0
else:
job_rating = 3.0
return job_rating
score(cf_job)
더 안 좋아졌다.
그럼 여러 변수를 기준으로 잡아 좀 더 세부적으로 그룹화하여 추천해준다면 정확도가 개선될 수 있을까?
# 성별, 직업 기준 추천
# 성별과 직업을 동시에 고려한 집단을 나눠서 예측값을 구하는 함수를 만들고, 정확도 계산 코드 작성하기
go_mean = merged_ratings[['movie_id','occupation','sex','rating']].groupby(['movie_id','occupation','sex'])['rating'].mean()
def cf_job_and_gender(user_id, movie_id):
if movie_id in rating_matrix:
job = users.loc[user_id]['occupation']
gender = users.loc[user_id]['sex']
if (job, gender) in go_mean[movie_id]: # 순서중요
go_rating = go_mean[movie_id][job,gender]
else:
go_rating = 3.0
else :
go_rating = 3.0
return go_rating
score(cf_job_and_gender)
웬걸;
베스트셀러, 성별만 그룹화, 직업만 그룹화한 것 보다도 더 안좋은 결과가 나왔다.
여기서 끝낼 수 없다. 책에서 더 나아가 다른 변수로 추천을 해보자.
users 데이터프레임에는 'age','sex','occupation','zip\_code' 컬럼이 있다.
단순히 생각했을때, 아무래도 영화 선호에는 성별과 나이가 영향을 미치지 않을까 싶다.
ag_mean = merged_ratings[['movie_id','age','sex','rating']].groupby(['movie_id','age','sex'])['rating'].mean()
def cf_age_and_gender(user_id,movie_id):
if movie_id in rating_matrix:
age = users.loc[user_id]['age']
gender = users.loc[user_id]['sex']
if (age, gender) in ag_mean[movie_id]:
ag_rating = ag_mean[movie_id][age,gender]
else:
ag_rating = 3.0
else:
ag_rating = 3.0
return ag_rating
score(cf_age_and_gender)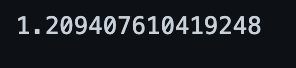
이것도 아니네...
이렇게 단순히 취향이 아닌 인구통계적 변수(직업, 성별, 나이 등)를 가지고 집단을 나눠서 추천을 하는 것은 성능이 좋지 못하다는 것을 알았다.
'추천시스템' 카테고리의 다른 글
| Content-based Filtering 이해하기 (0) | 2023.01.17 |
|---|---|
| TF-IDF (0) | 2023.01.17 |
| 사용자 정보가 없을때는? Best-Seller 방식! (0) | 2022.12.18 |
| 추천시스템의 개념과 기본 알고리즘의 개념 (0) | 2022.12.18 |