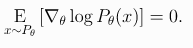차근차근 Spinning Up 톺아보기 Key Paper : DRQN
이번에 볼 논문은 DRQN이다. 논문 번역 식으로 포스팅하다보니 양이 많아지기도 해서 내가 읽은 대로 잊지않기 위해 정리한다. 먼저 DRQN 구조를 보자. DRQN은 DQN에서 첫번째 FC layer를 LSTM layer로 변경한 RNN+CNN 구조의 DQN이다. LSTM LSTM에 대해 이해하기 위해서 블로그를 참고하였다. RNN(Recurrent Neural Network)은 스스로 반복해서 이전 단계에 얻은 정보를 계속 기억하는 뉴럴네트워크이다. 이 그림이 RNN을 이해하는데 도움이 되었다. input X가 차례로 들어오면서 A에 누적되는것을 볼 수 있다. LSTM은 아래와 같은 구조로 생겼다. 각 요소들을 gate라고 하는데, 먼저 f는 forget gate, 잊는 것에 대한 게이트이다. sigm..