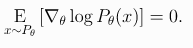Expected Grad-Log-Prob Lemma 이번 섹션에서, 우리는 policy gradient의 이론을 통해 널리 사용되는 중간 결과를 도출할 것이다. Expected Grad-Log-Prob을 줄여 EGLP라고 부를것이다. EGLP Lemma P_{\theta}가 확률변수 x에 대한 매개변수화된 확률 분포라고 가정하면, 다음식이 성립한다. 증명 Don't Let the Past Distract You PG를 위한 가장 최근의 표현을 보자. gradient 과정으로 인해 한 스텝 업데이트가 되면 모든 보상의 합인 Return에 비례하여 각 액션의 log-prob이 높아진다. 하지만 이것은 아직 별로 의미가 없다. 에이전트들은 결과에 따라 행동을 강화해야한다. 액션하기전에 얻은 보상은 하려는 액션..